
📊
High Link データチーム 紹介資料
目次はこちら
👋 こんにちは、High Linkのデータチームです!
データアナリスト
データ分析にスペシャリティを持つからこそ得られるインサイトを活かし、Issueの解像度を上げて戦略・推進に貢献します。
「事業部全員データアナリスト」のビジョンに向かい、施策単位のPDCAを回すための分析は自律的に行えるよう全社的にアプローチします。
データエンジニア・アナリティクスエンジニア
全社的にデータを活用して事業推進ができるよう、データ基盤の開発運用やデータ分析の民主化を推進していただきます。
事業をデータドリブンに推進するための分析基盤の構築や、データ基盤の構築、データマネジメントに関する業務をお任せします。
機械学習エンジニア
データを武器にした非連続的な事業成長を支える技術開発を行います。機械学習エンジニアとしてサービスの改善/開発を行っていただきます。主にデータを活用したアルゴリズムの開発とその基盤開発を担当していただきます。
Mission
データを武器に事業価値を創出する
High Linkは経営陣含めデータをとても大事にしています。
カラリア香りの定期便というtoCサービスにおいて、事業部全員がデータインフォームドな意思決定を基にしたユーザー体験の向上に向かっています。
カラリアの強みはデータです。
データの価値を高める・データから価値を創出することでグロースを支えます。
Vision
事業部全員がデータアナリストへ
組織・事業フェーズが拡大していくに従い、全社的なデータ利活用を加速させるためのData Enabling業務の重要性が増してきました。
私達は事業部全員がデータアナリストとして自律的にデータ分析を行い意思決定が行える組織を目指しています。
事業部全員がデータアナリストであるという文化を根付かせ、事業部メンバー自身がデータ分析を行うことにより意思決定における早さと正しさを両立できる強い組織を目指します。
特に、施策単位の分析で必要なデータを出して、インサイトを獲得、次のアクションにつなげるところまで自走できる状態にすることで組織がスケールしてもデータインフォームドな意思決定を高い強度で実現することが可能です。
データチームのData Enabling業務

チーム・プロジェクトに入り込みながらデータを活用した意思決定のサポートと同時に現場課題の吸い上げを行います。
現場との対話を通して課題の解像度を上げることを大切にしています。
私たちの目指す民主化レベル
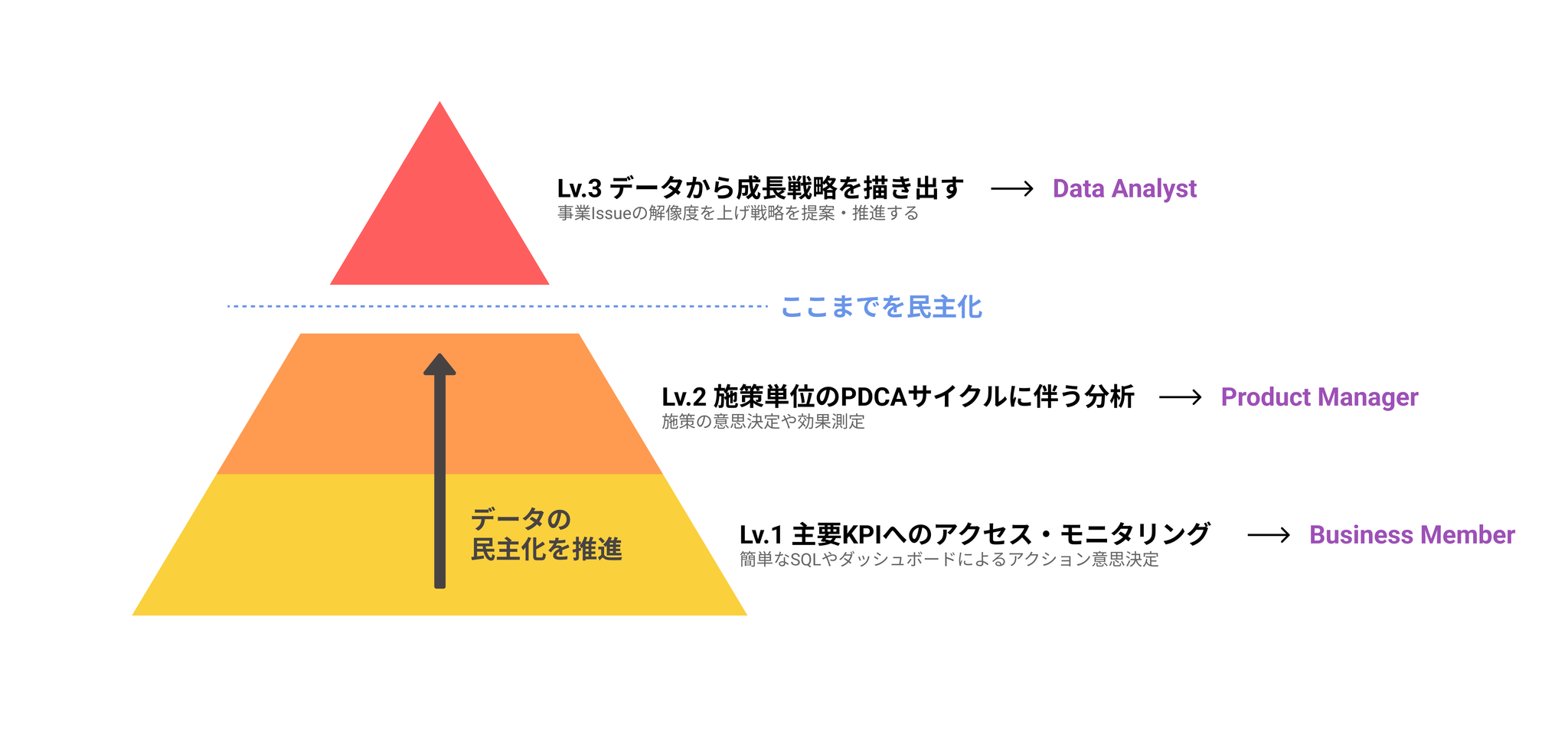
「データの民主化」と一口に言っても、どのレベルまでを期待するかは事業や組織の状況により変化すると考えています。
私たちはデータの活用レベルをピラミッドをベースに考え、下から順に 、 までを民主化していく方針です。
逆に、 はデータアナリストのスペシャリティであり、データアナリストに求める期待となっています。
データを活用して香りとの出会いを最適化する
香りは目に見えず、嗜好性も多種多様で、抽象度が高く言語化することも難しい領域です。
オフラインの売り場であればその場で試したり、販売員の説明を受けることができますがオンラインではそうはいきません。
私たちはデータを武器に、オンラインの売り場でもオフライン以上の香り選び体験を提供することを目指しています。
これまで見えなかった香りの可視化や、自分の嗜好性のカウンセリング、パーソナライズなど、「香り」というチャレンジングなドメインで今までなかった体験を生み出し、サービスのグロースを支えることに投資しています。
事業価値と連動しながら、技術検証から基盤の構築、APIの提供まで一気通貫して取り組むことができます。
業務内容・技術スタック
データ分析
職種: データアナリスト
データ分析のベースライン強化
- 「事業部全員データアナリスト」のビジョンに向かい、施策単位のPDCAを回すための分析は自律的に行えるよう全社的にアプローチします。
- 施策単位の分析で必要なデータを出して、インサイトを獲得、次のアクションにつなげるところまで自走できる状態にすることで組織がスケールしてもデータインフォームドな意思決定を高い強度で実現することを可能にします。
アクティビティ
- 施策PDCAサイクルの強化
- 効果測定・A/Bテストのサポート
- 基礎分析力(SQL)の強化
- データ分析を通じた意思決定の強化
データ分析のスペシャリティを活かした事業推進
- データ分析にスペシャリティを持つからこそ得られるインサイトを活かし、Issueの解像度を上げて戦略・推進に貢献します。
- 依頼されてデータを抽出するだけの役割としては想定しておらず、データ分析をした先のIssueやアクションに対してカウンターパートと同じ目線を持 ちながら伴走していくことを期待しています。
- 短期的な課題だけではなく、中長期を見据えた課題発見や解決策の提案も行います。
アクティビティ
- 事業・プロダクトに関するIssueの解像度を上げる
- データ分析を基にインサイトを獲得し、戦略・方針を提案する(貢献する)
- リーダーと伴走して「チームが進む方向性の精度を上げる」
- リーダーと伴走して「チームが進む意思決定を支援する」
- ユースケースに合わせたダッシュボードの整備(主にビジュアル面にコミットし、アクショナブルなダッシュボードを設計する)
技術スタック
| 開発言語 | SQL |
|---|---|
| DataWarehouse | BigQuery |
| ツール | Count, dbt, GA4, GoogleTagManager, LookerStudio, SpreadSheet, Google Slide, KARTE |
| その他 | GitHub Actions, Sentry |
データマネジメント
職種: アナリティクスエンジニア、データエンジニア
データを”持っているだけ”から”事業価値を産める状態”にする
- 保有しているデータから得られる事業価値を最大化するために、ビジネス要求に応えられるデータを整備します。
- データ活用のために足りないデータを整備したり、分析基盤の構築や、ダッシュボードの整備を通じて事業推進を加速します。
アクティビティ
- ユースケースに合わせた分析テーブルの設計・開発・運用(データモデリング)
- ユースケースに合わせたダッシュボードの整備(主に裏側の基盤整備にコミットし、拡張性・保守性を考慮した基盤を構築します)
- 施策単位のデータ分析を民主化するための基盤整備
- 現場の課題を吸い上げ、今後のユースケースを捉えて「足りない・使えない」データを開発チームと連携しながら整備していく
全社的なデータ基盤整備とデータガバナンス
- 全社的なデータ基盤をスコープとし、今後事業規模が拡大・組織規模が拡大してもスケーラブルに高品質なデータをすぐに出せる状態を維持できるようコミットします。
アクティビティ
- 事業規模・組織規模の拡張に対応するスケーラブルなデータ基盤の設計・構築・運用
- 事業規模・組織規模の拡張に伴うデータ活用のポリシー策定と展開
- データ品質の管理
- 重要指標の信頼性担保
- データをすぐに活用できるようメタデータの整備
技術スタック
| 開発言語 | SQL, yaml |
|---|---|
| DataWarehouse | BigQuery |
| ツール | dbt, Count, GA4, Fivetran, GoogleTagManager, SQLFluff, LookerStudio, SpreadSheet, KARTE |
| その他 | GitHub Actions, Sentry |
データサイエンス
職種: 機械学習エンジニア、データサイエンティスト
データを武器に香りとの出会いを最適化
- カラリアのビジョンである「香りとの出会いを最適化する」に対してデータを武器に体験強化していきます。
- レコメンド・パーソナライズといった機械学習プロダクトだけでなく、香りに限らずデータを活用したAPIの開発・改善もスコープに入ります。
- 開発・デリバリーの効率を上げるための基盤整備を行います(MLOps)
- アルゴリズム開発だけでなく、香りのディスカバリー体験を強化するためのデータづくりも行います。
アクティビティ
- レコメンド・パーソナライズ機能の開発・改善
- 診断機能・フレグランスプロフィールといった香りデータ資産を活かしたプロダクト開発・改善
- 香りのプロと連携した香りデータベースの設計・運用
- 香りに限らずデータを活用したAPIの開発・改善
- データを活用した機能の開発・デリバリー効率を上げる基盤整備(MLOps)
- 「香りの可視化」といったデータを活用した香り体験の開発
技術スタック
| 開発言語 | Python |
|---|---|
| フレームワーク | FastAPI |
| データベース | MySQL, Firestore, Google Cloud Storage (GCS) |
| DWH | BigQuery |
| インフラ | AWS, ECS, Docker, Terraform, GCP, VertexAI |
| その他 | GitHub Actions, Sentry, Dify(LLM) |
チームの取り組み
チームの取り組みはブログをご覧ください!
会社紹介資料
関わるサービス
メンバー紹介
正社員



関連ブログ
WE ARE HIRING!
募集中のポジション
